Knowledge Base
GPTWeb Two-Phase RAG & Crawler: Multimedia Knowledge at Scale
GPTWeb's two-phase RAG engine is purpose-built for the reality of how organizations actually store and share knowledge — across dozens of file types, media formats, and content systems. Rather than forcing a single ingestion model onto all content types, GPTWeb applies a two-phase approach that ensures every document, video, image, spreadsheet, and presentation is processed intelligently — and made conversationally retrievable at scale.
Phase One — Ingestion and Extraction: The first phase handles the heavy lifting of content extraction. GPTWeb ingests documents across a wide format range — PDFs, Word docs, Excel spreadsheets, PowerPoint decks, images, video transcripts, and flipbook presentations — and applies format-specific parsing to extract structured, semantic content from each. Large documents are automatically chunked into overlapping segments that preserve contextual continuity across section boundaries, ensuring that a 200-page technical specification answers questions just as accurately from page 180 as from page 2. Images are processed through vision-capable extraction pipelines. Video content is transcribed and segmented. Spreadsheets are parsed for data relationships, not just raw cell values. Every piece of content emerges from Phase One as clean, semantically rich, retrievable knowledge.
Phase Two — Curated Collections and Intelligent Routing: Phase Two is where GPTWeb's novel Knowledge Base architecture truly differentiates. Rather than dumping all ingested content into a single undifferentiated vector store, GPTWeb organizes knowledge into curated collections — purpose-built groupings of content that can be targeted to specific visitor personas, conversation contexts, or campaign workflows. A technical documentation collection serves engineers. A pricing and ROI collection serves executives. A competitive positioning collection serves sales conversations. Each collection can have its own retrieval priority, LLM instruction set, and persona-based routing rules — so the right content surfaces for the right visitor at exactly the right moment in their conversation.
GPTWeb Two-Phase RAG Engine — From Raw Content to Conversational Intelligence
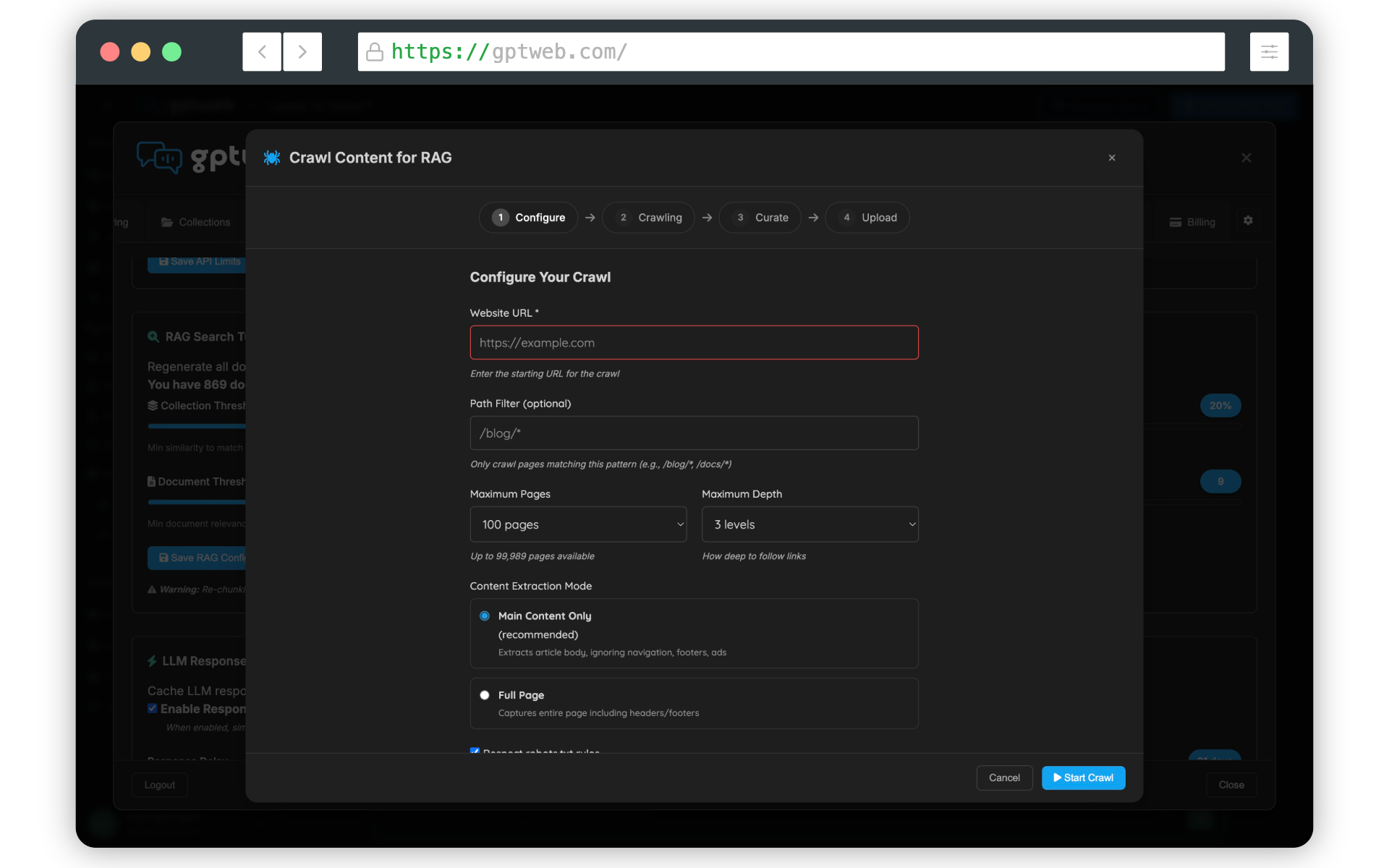
The Crawler — Fastest Path to Time-to-Value: For organizations with an existing website, GPTWeb's Knowledge Base (RAG) crawler eliminates the manual upload bottleneck entirely. Simply point the crawler at your domain, configure depth and page scope, and GPTWeb automatically extracts, parses, chunks, and indexes every page into your knowledge base — transforming years of existing web content into a live conversational intelligence layer in a matter of minutes. Teams that would have spent weeks curating content manually go live in a single session. The crawler continuously monitors for content changes, ensuring the knowledge base stays current as your site evolves.
Docs, PDF, XLSX, Images, Video, Flipbook
Supported File Types
Auto-Chunked with Context Continuity
Large Document Handling
Multi-Collection Persona Routing
Collections Architecture
Minutes Not Weeks
Time to Value via Crawler
> A note for executives: The business value of GPTWeb's two-phase RAG is fundamentally about unlocking the knowledge your organization already has. Most companies have years of product documentation, sales collateral, technical guides, training videos, and competitive research sitting in static repositories — generating zero value for website visitors. GPTWeb's RAG engine converts that dormant institutional knowledge into a live, conversational, 24/7 revenue asset. Every document your team has ever produced becomes a potential touchpoint in a visitor's buying journey — scored, segmented, and capable of generating a DQL without any human intervention. The ROI is not just faster content delivery. It is the compounding pipeline value of making your entire knowledge base work for revenue.
Ready to convert your existing content into a live conversational knowledge engine? Getting Started walks through the full setup — or [](gptweb://modal/demo) to see the crawler and RAG engine in action. GPTWeb is the future of engagement, websites, and marketing automation combined — built for the AI era, built for now.