Knowledge Base
Knowledge Sources & Loading Best Practices
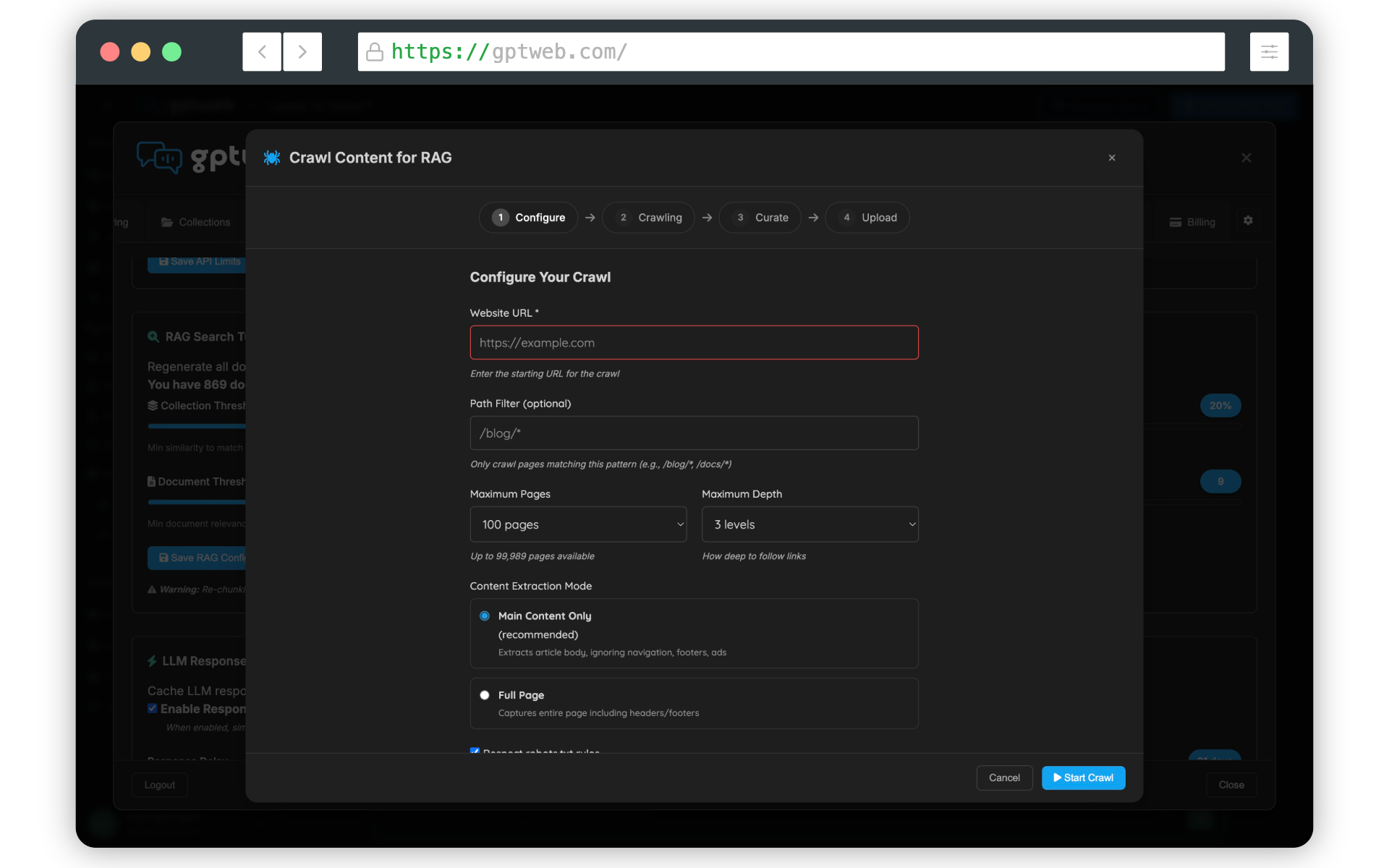
Hello! GPTWeb ingests information from multiple sources to build a rich, conversational understanding of your organization. The primary sources include uploaded documents (PDFs, Word docs, text files, presentations), website content via the built-in crawler (you set the starting URL, depth limits, and include/exclude patterns), structured prompt library entries curated by admins, images and videos with metadata and keywords, and visitor intelligence captured through conversations and persistent profiles. Together these feed the RAG layer so the assistant answers from your actual content rather than generic AI knowledge. Learn more about What is GPTWeb? and how to start with Getting Started.
5+
Ingest Source Types
2-3
Recommended Crawl Depth
Targeted
Goal: Curated Pages
Best practices for loading content, : keep your knowledge base focused and curated rather than dumping entire sites or massive files. Set sensible crawler depth limits, use exclude patterns to skip irrelevant URLs (login pages, archives, tag pages), and review crawl results before committing them to RAG. Smaller, targeted knowledge bases produce faster searches, fewer tokens per query, and more accurate answers. Re-crawl periodically to keep content fresh as your site evolves. Explore practical Use Cases or get hands-on with a [](gptweb://modal/trial).
GPTWeb is the future of engagement, websites and marketing automation combined that is built for the AI era, built for now.